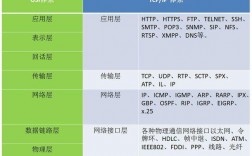
消息队列是怎么实现的,能给出思路
看你使用什么编程语言,参考一下
消息队列技术是分布式应用间交换信息的一种技术。消息队列可驻留在内存或磁盘上,队列存储消息直到它们被应用程序读走。通过消息队列,应用程序可独立地执行--它们不需要知道彼此的位置、或在继续执行前不需要等待接收程序接收此消息。

1. 线程使用场景
(1)流水线方式。根据业务特点,将一个流程的处理分割成多个线程,形成流水线的处理方式。产生的结果:延长单一流程的处理时间,提高系统整体的吞吐能力。
(2)线程池方式。针对处理时间比较长且没有内蕴状态的线程,使用线程池方式分流消息,加快对线程消息的处理,避免其成为系统瓶颈。

线程使用的关键是线程消息队列、线程锁、智能指针的使用。其中以线程消息队列最为重要。
简单的线程消息队列实现 - 闯爷88 - 博客园
https://www.cnblogs.com/lijingcheng/p/4454876.html

我想你的问题是想问“如何自己设计”一套消息队列框架,对吗?
现实中已经有了很多面向不同系统的消息队列软件,成熟的消息队列如kafka,rocketmq等。其实现语言也是多种多样,你可以从Github之类的地方获得这些软件来学习和使用。
而自己设计一套消息队列,因为面对不同的应用场景,其要求是不一样的,没有能够适用所有场景的消息队列。而下面我简单讲讲一个普通的、稍微完善的消息队列框架应该设计哪些东西,主要介绍一下基本功能,思想和设计。希望能帮到你。
消息队列主要是为了系统解耦,先说说设计上需要考虑哪些。
1、一个比较完整的消息队列需要考虑以下功能(不完全列表)
消息收发机制、消息堆积处理、、消息持久化、消息可靠投递(至少保证一次投递,以及重复投递的处理)、Topic支持(唯一或多Topic)、多消费者投递(同一Topic消息)、投递回溯、集群和负载均衡等性能设计、事务支持、监控和告警等维护功能
大概有这些吧。
以上是设计需要考虑的东东。
再简单说说实现要考虑什么。
2、实现的话,主要从 协议、转储、消费 简单说说。
kafka原理和架构解析
Kafka是一种高性能、分布式、可扩展的消息系统,具有高吞吐量和低延迟的特点。它采用发布-订阅模式,将数据以分区的方式存储在集群中,支持并发读写,具备数据备份和故障转移的机制。
Kafka的架构包括了生产者、消费者和broker三部分,其中broker是Kafka集群中的服务节点,生产者把数据写入broker,消费者从broker中读取数据,而Zookeeper则用于协调Kafka集群中的各个节点。
Kafka是一种分布式流处理平台,它具有高吞吐量、可扩展性和持久性的特点。下面是Kafka的原理和架构解析:
1. 基本概念:
○ Topic(主题):消息的类别或者主题,可以理解为消息的容器。
○ Producer(生产者):负责向Kafka的Topic发送消息。
○ Consumer(消费者):从Kafka的Topic订阅并消费消息。
○ Broker(代理):Kafka集群中的每个节点,负责存储和处理消息。
○ Partition(分区):每个Topic可以分为多个分区,每个分区在不同的Broker上存储。
○ Offset(偏移量):每个消息在分区中的唯一标识。
2. 架构:
○ Kafka集群由多个Broker组成,每个Broker可以在不同的机器上。
到此,以上就是小编对于分布式 消息队列的问题就介绍到这了,希望介绍的2点解答对大家有用,有任何问题和不懂的,欢迎各位老师在评论区讨论,给我留言。
 微信扫一扫打赏
微信扫一扫打赏