hadoop+spark构建的高可用大数据的功能
hadoop+spark构建的高可用大数据具有以下功能:高可用、分布式存储、数据处理和分析。
首先,hadoop+spark构建的高可用大数据系统能够实现高可用性,即在某个节点发生故障时,系统能够自动切换到其他节点,保证数据的持续可用性。
其次,这种系统采用分布式存储的方式,将大量的数据分散存储在多个节点上,提高了数据的安全性和可靠性。
即使某个节点发生故障,数据仍然可以从其他节点中恢复。
此外,hadoop+spark还提供了强大的数据处理和分析能力。
Hadoop通过分布式计算框架MapReduce,能够高效地处理大规模数据。
而Spark则提供了更快速的数据处理和分析能力,支持实时计算和复杂的数据处理任务。
总之,hadoop+spark构建的高可用大数据系统具有高可用性、分布式存储、数据处理和分析等功能,能够满足大规模数据处理和分析的需求。
Spark是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架,Spark基于map reduce算法实现的分布式计算,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的map reduce的算法。 优势应该在于分布式架构比较相似能快速上手吧
-图1")
spark可以定义方法吗
Spark是一个开放源代码的分布式计算框架,是基于Java编程语言实现的。在Spark中,可以通过定义函数来实现方法的定义。函数定义的格式与Java中的方法定义类似,可以指定函数的名称、参数列表和返回值类型。通过函数的定义,可以在Spark中实现各种数据处理和计算任务。Spark提供了丰富的API,包括RDD、DataFrame和Dataset等,可以灵活地实现不同的数据处理需求。因此,通过定义函数,可以更好地利用Spark的强大功能和灵活性,实现高效的数据处理和计算。
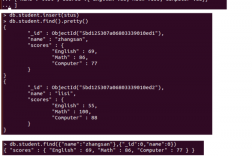
1亿数据怎么做统计
处理1亿数据进行统计可以采取以下几种方法:
1. 数据分片:将1亿数据分成多个较小的数据块,然后分别对每个数据块进行统计。这样可以减少单个数据块的大小,提高处理效率。
-图2")
2. 并行计算:利用多台计算机或多个处理单元进行并行计算,将数据分配给不同的计算单元进行统计。这样可以同时处理多个数据块,加快处理速度。
3. 数据压缩:对数据进行压缩,减少数据的存储空间和传输时间。可以使用压缩算法如gzip或LZO等进行数据压缩,然后再进行统计。
4. 数据索引:对数据进行索引,以便快速查找和统计。可以使用数据库索引或建立自定义索引结构,加快数据的访问和统计速度。
-图3")
sparksql结构化数据查询的过程是什么
SparkSQL结构化数据查询的过程包括以下几个步骤:
首先,将查询语句解析成逻辑计划,然后将逻辑计划转换成物理计划,接着将物理计划转换成RDD的执行计划,最后执行RDD的计划并将结果返回给用户。在整个过程中,SparkSQL会利用Catalyst优化器对计划进行优化,包括谓词下推、列裁剪和投影消除等技术,以提高查询效率和性能。
到此,以上就是小编对于利用spark实现高效的大数据处理和计算方法的问题就介绍到这了,希望介绍的4点解答对大家有用,有任何问题和不懂的,欢迎各位老师在评论区讨论,给我留言。
 微信扫一扫打赏
微信扫一扫打赏